- Splash在爬虫中的应用背景
Python爬虫框架Scrapy,因其语言易懂,配置简单和异步操作等优势,越来越多的受到爬虫爱好者的喜欢。当然本文讲解的内容和原理,也适用于其他语言所写的爬虫。
但是随着爬虫技术的升级,反扒技术也越来越高明。除了验证码以及限制爬取频率外,越来越多网站使用页面动态技术来阻挠爬虫的直接侵袭。动态页面是与静态页面相对应的概念。
静态页面 : 网页的主要(或所有)内容是以文本形式直接嵌入HTML框架中。这种页面,直接wget,然后就能从中获取我们需要的内容。
动态页面 : 只有少部分(往往不是我们需要的)内容是文本形式直接嵌入HTML框架中。其余大部分核心数据是以javascript的形式在页面加载完成以后或由用户的页面操作行为触发,去服务端加载之后,动态渲染到页面上的。这种页面,wget到的页面不会包含后面渲染的数据,用处不大。
虽然采用Hack方式直接debug页面javascript,会有一定概率破解页面关键细节,但是存在以下劣势:
- Debug需要极高的技术能力,而且网站管理员随时可以更新反扒策略,一次hack并不能保证始终有效
- 很多网站对通过Debug获取到的网站资源(就好像打开了一扇直通网站后台核心数据的大门),一般都是禁止爬虫爬取的(robots.txt)。关于robots.txt,我本人是严格遵守的,因为某种程度上,爬虫就是游走在道德甚至法律边缘的行为。近期有诸多因爬虫而入最罪的报道。所以,小心使得万年船,别人不想要你直接拿的东西,不要直接拿!
所以就出现了,对动态页面进行渲染的组件。你可以将这种组件理解成一个特别的浏览器。
那我就造一个浏览器好了?没错!确实是这样。可以这么说,网站不允许我们直接到后台拿数据,那么我们就通过正常浏览页面的方式来获取到我们需要的数据。虽然费事费力,但是安全,而且这是真正意义上的爬虫,hack的方式属于偷窃。下面要讲的所有的动态解析组件都起到了浏览器的作用,确切的说是像浏览器解析动态页面一样解析动态页面。主要介绍Selenium 和 Splash
-
首先登场的是UI自动化测试界的扛把子: Selenium。
它可以控制浏览器的行为,并获取浏览器中页面数据。要在Python中使用Selenium,你需要首先有一个浏览器(推荐chrome,firefox也是支持的),然后安装一个 chrome的web-driver 驱动,这样selenium就可以操控chrome了。
通过在selenium控制的浏览器中访问需要爬取的网页,等网页动态渲染完成,就可以获取我们需要的数据了。关于一些细节,本文不介绍,网上有很多,自己查。
但是很多人可能会问,我非得打开一个浏览器才能实现selenium的爬虫吗? 在纯命令行界面就不能用了吗? 这个问题很好,就是因为好多人都有这样的疑惑,所有后面出现了无头浏览器。 -
首先出现的是一个专门的组件,叫 PhantomJS。实现的功能跟selenium类似,但是不需要UI界面。后面chrome也支持无头模式了(我不确定是chrome先支持无头还是现有的PhantomJS)。
反正现在的结果就是PhantomJS暂停维护了,而且越发看不到任何复出的可能。chrome的无头模式我用过,体验不错。注意,无头模式还是需要安装chrome浏览器的,只不过不显示UI界面。
但是浏览器+驱动的方式,还是有点麻烦,虽然不需要显示UI界面了。偷懒是人类进步的动力,所以慢慢的就有了下面要讲的splash。 -
现在的splash几乎都是以docker的形式安装和分发的,这就更像是一个黑盒了。Splash就像是一个代理,用户将需要爬取的页面,放进去,splash代理用户去访问页面,并按照用户需要的方式渲染页面,将渲染之后的页面数据返回给用户。
目前Splash几乎可以替代selenium+web-driver的方式了。
2. Splash的具体操作
上面提到splash会按照用户需要的方式渲染页面。那是怎么渲染的呢?具体来说,splash会使用lua脚本执行用户定义的操作。splash提供了好多api接口供用户使用,而且可以把javascript脚本或操作嵌入lua脚本。举一个例子。
-
配置启动splash之后,可以按照默认方式访问splash: http://localhost:8085/,
-
然后在输入框中输入想要渲染的页面: http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
最后是重点,将我们需要的操作放入Script下面(默认会有一个脚本,你可以点击Render试一下),实例操作如下,代码内容不介绍,自己看:
function main(splash, args) assert(splash:go(args.url)) assert(splash:wait(3)) local btn_select_free = splash:select('#custom-fields') btn_select_free:mouse_click() assert(splash:wait(0.5)) splash:send_text("总市值") splash:send_keys("<Enter>") assert(splash:wait(0.5)) local btn_sort = splash:select('[aria-label="总市值"]') btn_sort:mouse_click() assert(splash:wait(0.5)) local btn_sort_desc = splash:select('[aria-label="总市值"]') btn_sort_desc:mouse_click() assert(splash:wait(1)) js1 = string.format('document.querySelector(".paginate_input").value=1', args.page) js2 = string.format('document.querySelector(".paginte_go").click();', args.page) splash:runjs(js1) assert(splash:wait(0.5)) splash:runjs(js2) assert(splash:wait(1)) return { html = splash:html(), png = splash:png(), har = splash:har(), } end
- 渲染之后,就得到了我们需要的一个页面,如下图所示。
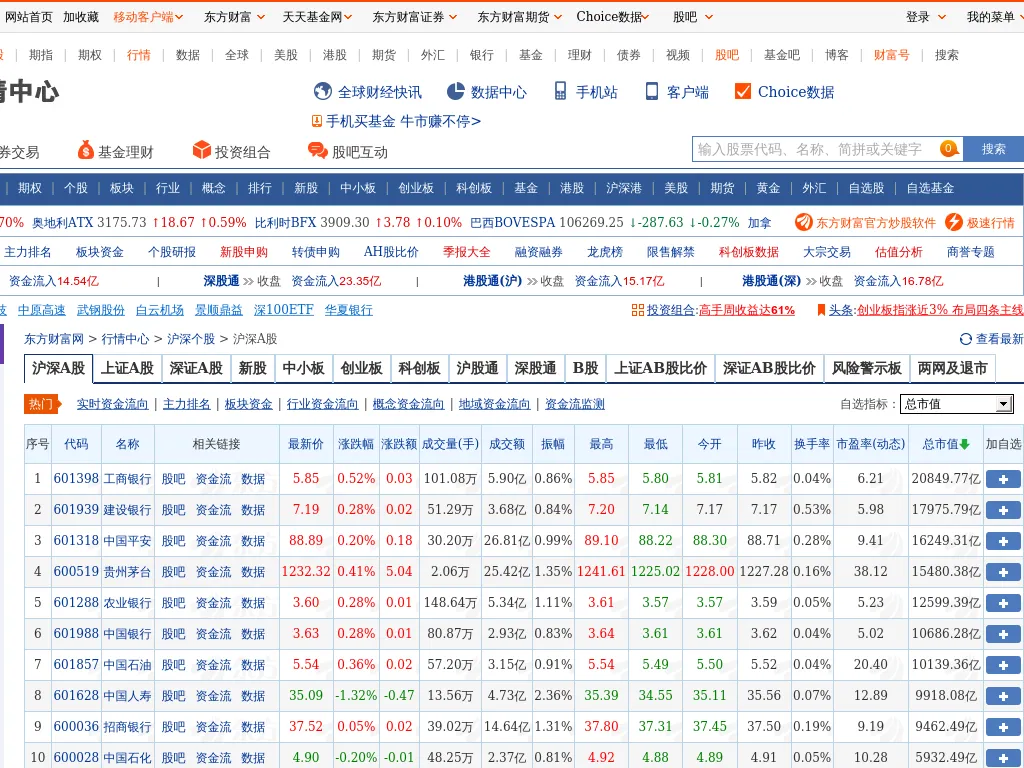
以上就是一个手动实现splash渲染的过程示例。当然在具体爬虫(scrapy)中需要将以上过程脚本化。其实最难的操作脚本已经完成了。剩下的就是把操作脚本填入scrapy-splash的框架即可,一个示例如下:
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board' lua_script=""" function main(splash, args) assert(splash:go(args.url)) assert(splash:wait(3)) local btn_select_free = splash:select('#custom-fields') btn_select_free:mouse_click() assert(splash:wait(0.5)) splash:send_text("总市值") splash:send_keys("<Enter>") assert(splash:wait(0.5)) local btn_sort = splash:select('[aria-label="总市值"]') btn_sort:mouse_click() assert(splash:wait(0.5)) local btn_sort_desc = splash:select('[aria-label="总市值"]') btn_sort_desc:mouse_click() assert(splash:wait(1)) js1 = string.format('document.querySelector(".paginate_input").value=1', args.page) js2 = string.format('document.querySelector(".paginte_go").click();', args.page) splash:runjs(js1) assert(splash:wait(0.5)) splash:runjs(js2) assert(splash:wait(1)) return { html = splash:html(), png = splash:png(), har = splash:har(), } end """ yield SplashRequest(url,endpoint = 'execute',args = {'lua_source': lua_script ,'images': 0,'timeout': self.rendering_page_timeout},callback=self.parse)
3. 总结
scrapy + splash 的 python爬虫,容易上手,快速出成果。但是要熟悉,需要做很多的联系,尤其是scrapy,最好看一下源代码,不然很多细节容易搞不清楚,比如异步(yield)等等。


本文作者:王海生
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!